I’ve been arguing with myself about the proper way to split up some code that has related concerns. The code in question relates to fetching secrets and doing encryption. The domains are clearly related, but the libraries aren’t necessarily coupled. The encryption library needs secrets, but secrets are simple enough to pass across in an unstructured fashion.
As I mentioned before, we are integrating Vault into our stack. We are planning on using Vault to store secrets. We are also going to be using their Transit Encryption Engine to do Envelope Encryption. The work to set up the Envelope Encryption requires a real relationship between the encryption code and Vault.
There are a couple of options for how to structure all of this. There are also questions of binary compatibility with the existing artifacts, but that’s bigger than this post. The obvious components are configuring and authenticating the connection to Vault, the code to fetch and manage secrets, the API for consuming secrets, and the code to do encryption. I’m going to end up with three or four binaries, encryption, secrets, secret API, and maybe a separate Vault client.
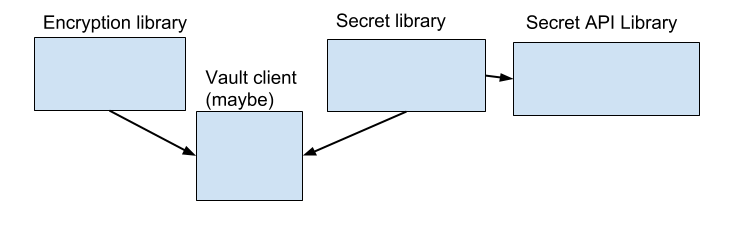
That would be the obvious solution, but the question of what the Vault client exposes is complex, given that the APIs being used by the encryption and secrets are very different. It could expose a fairly general API that is essentially for making REST calls and leaves parsing the responses to the two libraries, which isn’t ideal. The Vault client could be a toolkit for building a client instead of a full client. That would allow the security concerns to be encapsulated in the toolkit, but allow each library to build their own query components.
Since the authentication portion of the toolkit would get exposed through the public APIs of the encryption and secret libraries, that feels like a messy API to me and I’d like to do better. There seems like there should be an API where the authentication concerns are entirely wrapped up into the client toolkit. I could use configuration options to avoid exposing any actual types, but that’s just hiding the problem behind a bunch of strings and makes the options less self-documenting.
Like most design concerns there isn’t a real right answer. There are multiple different concerns at odds with each other. In this case you have code duplication vs encapsulation vs discoverable APIs. In this case code duplication and encapsulation are going to win out over discoverable APIs since the configuration should be set once and then never really changed, as opposed to the other concerns which can contain the long term maintenance costs of the library since it will likely be used for a good while to come.
